GPU Metrics
GPU metrics complement profiles by providing high-level visibility into GPU performance, resource utilization, and hardware health. Use metrics to form hypotheses about performance issues, then dive deeper with GPU profiling for detailed analysis:
- Metrics help you form hypotheses by revealing performance trends and identifying potential bottlenecks
- Profiling provides detailed CUDA kernel-level analysis to validate hypotheses and pinpoint optimization opportunities
Together, they enable a complete GPU performance analysis workflow from hypothesis formation to detailed optimization.
Metrics are designed for monitoring purposes. If you need deep visibility into your code and how efficiently it runs on GPUs, use profiling. A typical workflow is to start from an interesting data point on high or low power or memory consumption, click on it, and navigate to the corresponding GPU profiles for detailed analysis.
Note that Tensor Core, SM Efficiency, and SM Occupancy metrics are only available on data center GPUs such as H100s and H200s.
Enabling GPU Metrics
To enable GPU metrics collection, add the --enable-gpu-metrics flag to your profiler configuration. See the installation guide for detailed instructions on each method:
- Helm Installation - Use
--setto add--enable-gpu-metricsand--nvml-auto-scanto the profiler args - Docker Installation - Include
--enable-gpu-metricsand--nvml-auto-scanin your docker run command - Binary Installation - Add
--enable-gpu-metricsand--nvml-auto-scanto your command line arguments - Systemd Service - Include
--enable-gpu-metricsand--nvml-auto-scanin your service file
Note: Use
--nvml-path=/path/to/libnvidia-ml.soinstead of--nvml-auto-scanif you know the exact NVML library path.
Available GPU Metrics
| Category | Metric | Description |
|---|---|---|
| Performance | GPU Utilization | Percentage of time the GPU was actively processing workloads |
| GPU Consumer | GPU utilization broken down by process (grouped by main executable) | |
| SM Efficiency* | Streaming Multiprocessor (SM) efficiency as a percentage | |
| SM Occupancy* | Streaming Multiprocessor (SM) occupancy as a percentage | |
| Tensor Core Utilization* | Utilization percentage of Tensor Cores, specialized processing units optimized for AI/ML workloads | |
| Memory | GPU Memory Utilization | Percentage of GPU memory (VRAM) currently in use |
| GPU Memory Consumer | GPU memory utilization broken down by process (grouped by main executable) | |
| Hardware | GPU Power Usage | Current power consumption of the GPU in watts |
| GPU Temperature | Current GPU temperature in degrees Celsius | |
| Data Transfer | PCIe Transmission Throughput | PCIe data transfer rates between the GPU and system (received and transmitted) |
| NVLink Transmission Throughput | NVLink data transfer rates between GPUs (received and transmitted) |
* Available only on data center GPUs (H100s, H200s, etc.)
How GPU Metrics Collection Works
zymtrace uses NVIDIA's NVML (NVIDIA Management Library) to collect GPU metrics. NVML provides a C API for monitoring and managing NVIDIA GPU devices, enabling us to gather real-time performance, utilization, and health data directly from the GPU hardware.
Using GPU Metrics with GPU Profiles
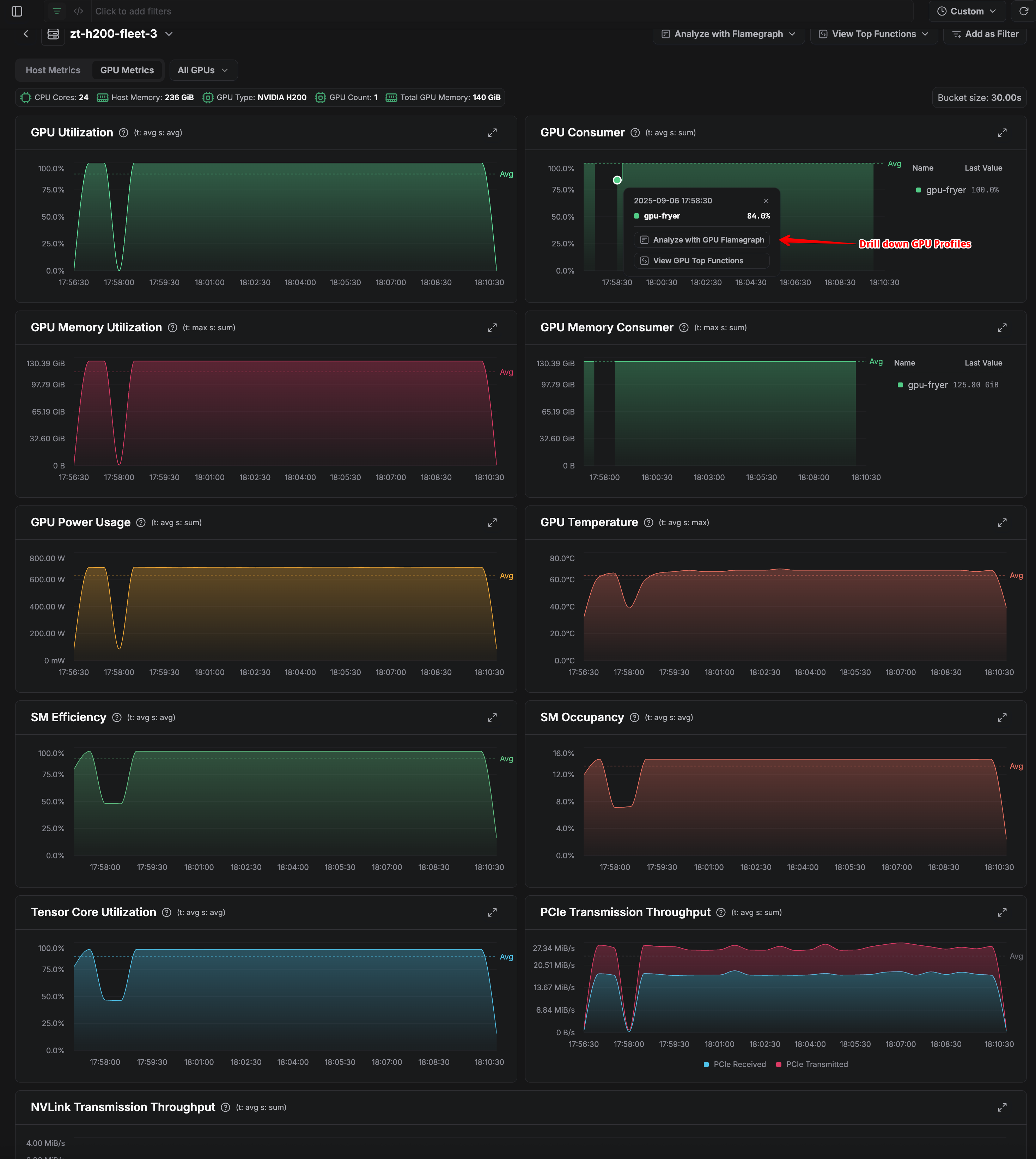
Once GPU metrics are enabled, you can navigate to Top Entities and select your GPU host to see the metrics dashboard. This view displays real-time and historical data across all categories, giving insight into patterns in utilization, memory usage, and power consumption. By examining these trends, you can identify anomalies that might indicate performance issues. Clicking on specific data points then allows you to drill down into detailed GPU profiles.
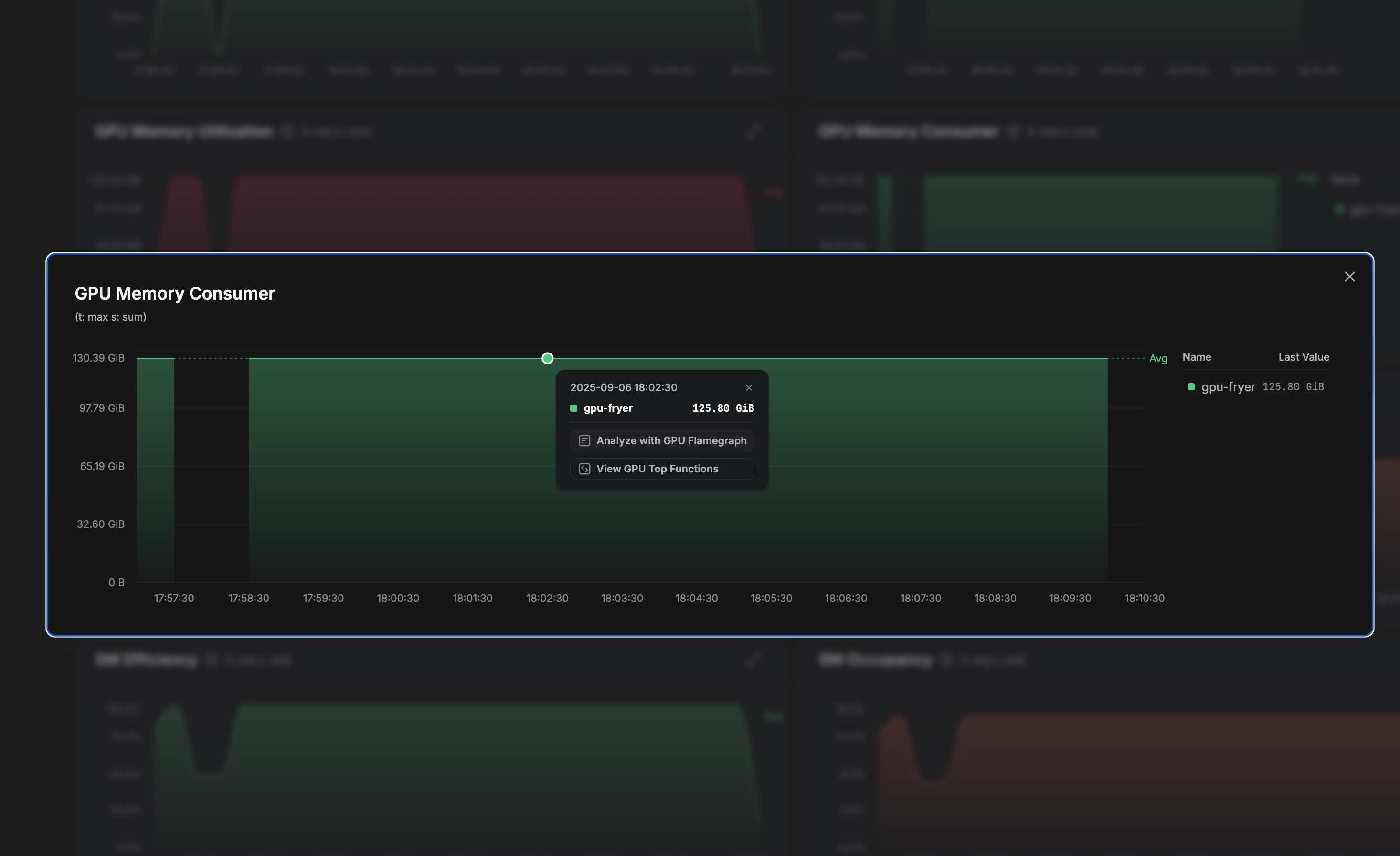
For more granular investigation, the metrics also provide process-level breakdowns. Expanding individual metric widgets shows which processes are consuming the most resources. For example, in our analysis, Hugging Face's GPU Fryer consumes roughly 90% of available GPU memory. This immediately suggests a hypothesis: high memory pressure could be contributing to performance degradation. Metrics like this guide the investigation toward examining memory allocation patterns and kernel execution characteristics for the process in question.
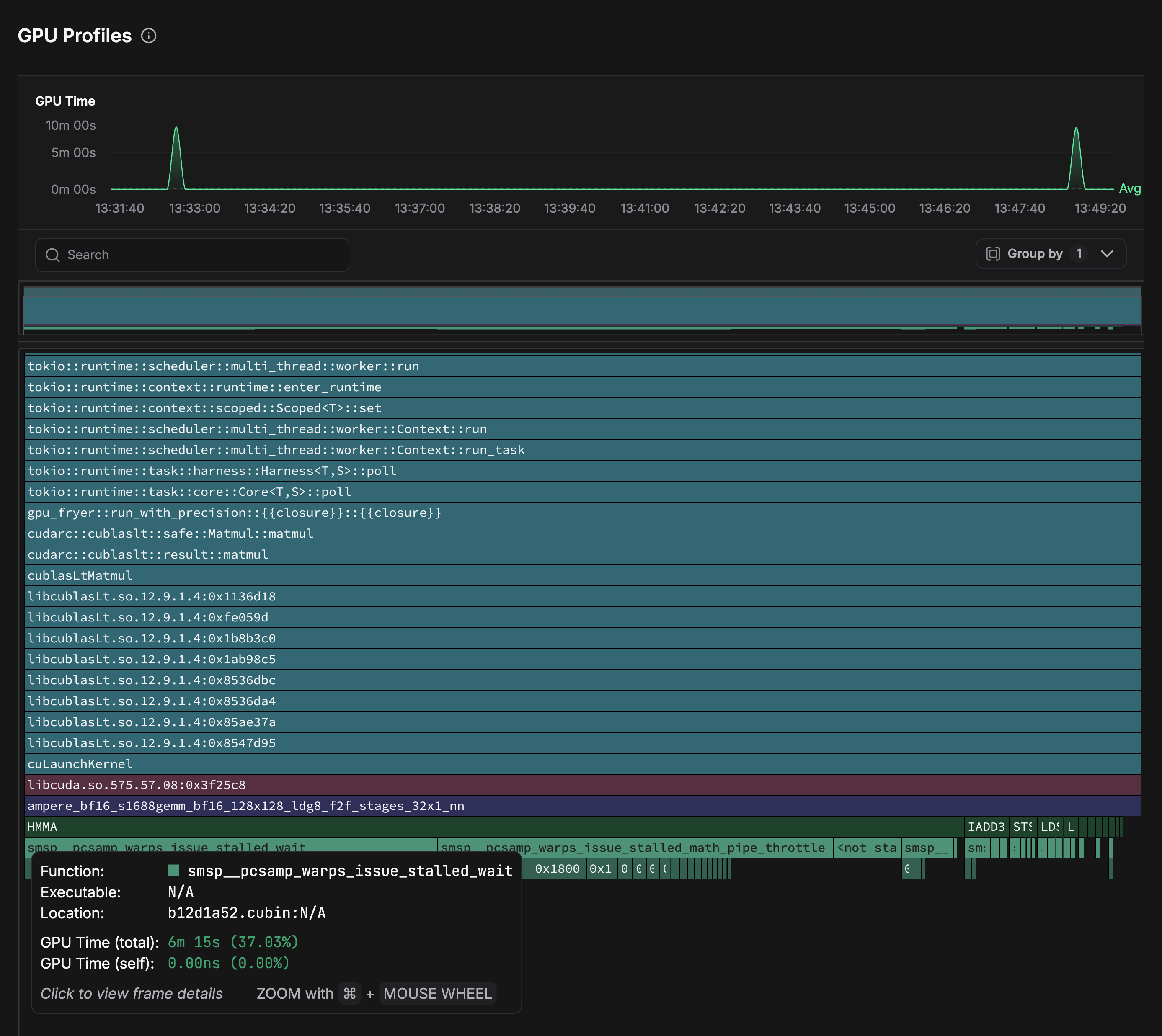
Clicking on the relevant data point, you can analyze the data with GPU profiles. The flamegraph for GPU Fryer, a Rust-based GPU stress-testing tool, shows that it orchestrates asynchronous matrix multiplications through the CUDA runtime. The primary kernel invoked is
ampere_bf16_s1688gemm_bf16_128x128_ldg8_f2f_stages_32x1_nn
This kernel is launched via cublasLtMatmul from libcublasLt.so and is a batched BF16 GEMM implementation optimized for Ampere Tensor Cores.
At the instruction level, execution is dominated by HMMA (Half-precision Matrix Multiply-Accumulate) SASS instructions, which perform the core fused matrix operations. Scalar instructions such as IADD3 handle indexing, loop counters, and control flow.
The main performance bottleneck is revealed by the smsp__pcsamp_warps_issue_stalled_wait stall reason. This indicates that the kernel is waiting for a fixed latency dependency to complete. In other words: it is waiting for the result of another instruction to be available for the next computation. It generally shows up as top contributor in kernels that are already very well optimized, which is to be expected given that this specific kernel is provided by Nvidia itself as part of cuBLAS. Further optimization may be achieved by reordering instructions in a way that more computation is done while the previous computation is still in progress or switching to lower latency instructions if they are available.
A second stall reason is reflected in smsp__pcsamp_warps_issue_stalled_math_pipe_throttle, which shows that Tensor Core pipelines are heavily utilized but limited by insufficient overlap between arithmetic and memory operations. Even with a 32-stage pipeline designed to hide latency, the number of active warps is sometimes too low to fully exploit the GPU, and scheduler overhead prevents seamless switching to ready warps.
Based on this analysis, several optimization strategies emerge. Improving execution patterns to allow better warp parallelism, refining memory access through a more efficient ring buffer, and adjusting kernel launch parameters to increase occupancy and improve arithmetic-memory overlap can all reduce stalls and boost throughput. Additionally, distributing workloads across multiple GPUs can help alleviate per-GPU memory pressure and further improve performance.
Understanding the Metrics
Performance Metrics
GPU Utilization provides the overall percentage of time your GPU is actively processing workloads. This is a key indicator of how well your GPU resources are being utilized.
GPU Consumer breaks down GPU utilization by process, helping you identify which applications or workloads are consuming the most GPU resources.
SM Efficiency measures how effectively the Streaming Multiprocessors are being utilized. It indicates the percentage of cycles where the SM has one or more of its assigned warps actively making progress in their execution. Low efficiency might indicate suboptimal kernel configurations or inefficient memory access patterns.
SM Occupancy shows the percentage of maximum possible threads that are active on the SMs. While higher occupancy often correlates with better performance, this isn't always the case.
Tensor Core Utilization is particularly important for AI/ML workloads, as it shows how well you're leveraging the specialized hardware designed for these operations.
Memory Metrics
GPU Memory Utilization shows how much of your GPU's VRAM is currently in use. Monitoring this metric helps prevent out-of-memory errors and optimize memory allocation strategies.
GPU Memory Consumer provides a breakdown of memory usage by process, helping identify which applications consume the most memory.
Hardware Metrics
GPU Power Usage and GPU Temperature are crucial for understanding the thermal and power characteristics of your workloads. These metrics help with capacity planning and thermal management strategies.
Data Transfer Metrics
PCIe Transmission Throughput measures data movement between the GPU and system memory, which can become a bottleneck for data-intensive workloads.
NVLink Transmission Throughput (available on supported hardware) measures high-speed GPU-to-GPU communication, which is critical for multi-GPU workloads.